Какие данные необходимо собирать для продвинутой post-view аналитики? Опыт DataGo! Consulting

У нас накопилось так много знаний и материалов про post-view аналитику, что мы совместно с консультантом DataGo! Consulting Ксенией Макаровой выпускаем наш третий кейс про data-driven подход к анализу post-view аналитики, в котором мы расскажем:
- Что такое продвинутая post-view аналитика и для чего она нужна?
- Какие инструменты помогут собрать все необходимые данные?
- Как построить инфраструктуру для продвинутой post-view аналитики?
Два предыдущих материала вы найдете по ссылкам:
Как неэффективные процессы влияют на бюджет и качество post-view аналитики — кейс DataGo! Consulting
Что такое продвинутая post-view аналитика?
Продвинутая post-view аналитика - это способ анализа эффективности медийных размещений, который помогает ответить на следующие вопросы:
- Какой графический баннер показывает лучшие результаты?
- Какая рекламная кампания имеет самый высокий показатель ROI?
- Сколько заработала компания с каждой рекламной площадки?
За счет продвинутой post-view аналитики вы сможете принимать обоснованные управленческие решения, опираясь на конкретные метрики и показатели.
Ксений Макарова, DataGo! Consulting
Но для того, чтобы полноценно использовать данный подход, необходимо определиться:
- Какие именно данные мы хотим собирать?
- Какие выводы они помогут нам сделать?
Чтобы определиться с ответами на эти вопросы, мы отталкиваемся от конечных целей: цель любого бизнеса и рекламной кампании - доход.
Соответственно, нам важно понять, принесла ли медийная реклама доход.
На какие метрики необходимо ориентироваться?
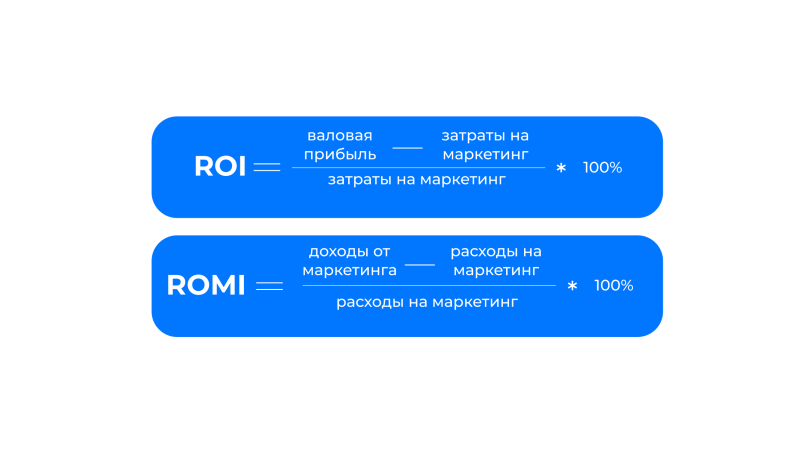
- Необходимо посчитать окупаемость (ROI/ROMI). Для этого нам нужны расходы (из рекламного кабинета) и доходы (из CRM).
Если расходы мы можем явно отнести к конкретной рекламной кампании, таргетингу и креативу, то с доходами все намного сложнее, так как помним, что медийная реклама приносит в 90% случаев post-view конверсии, т.е. нет прямой связи между просмотром креатива и действием пользователя на сайте.
Для подсчета дохода от медийной рекламы, необходимо собрать данные о пользовательских событиях после просмотра медийного креатива до конечной конверсии.
Как это сделать?
- С помощью пикселей AdTracker (Например, Adriver, Weborama);
- Промечаем каждое медийное объявление, и в момент его показа пользователю будет присваиваться cookie-файл, который при заходе пользователя на сайт поможет определить всех пользователей, которые ранее видели медийное объявление;
- Устанавливаем пиксель трекера на посещение страниц и на целевые действия
Данный пиксель будет передавать на свои сервера данные о всех пользователях, которые зашли на сайт и присваивать им признак “видел медийную рекламу” или “не видел медийную рекламу”. Также трекер свяжет показ медийной рекламы с конкретным целевым действием (конверсией)
Для более глубокого изучения аудитории, которая видела медийную рекламу мы можем передавать любые мета-данные из системы аналитики о пользователе помимо тех, что собирает трекер.
Как построить инфраструктуру для продвинутой post-view аналитики
Далее мы опишем основные шаги, с которыми вам необходимо будет столкнуться при настройке инфраструктуры для продвинутой post-view аналитики.

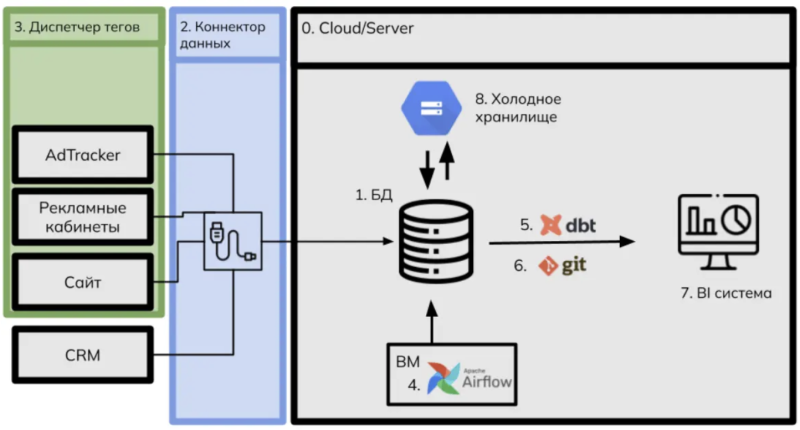
Шаг 1. Единая база данных
Доступ ко всем данным в едином месте - это маст хэв.
У аналитика должна быть возможность обращаться в едином хранилище к расходам, доходам, пользовательским событиям и данными от трекера. Для этого необходимо обеспечить стриминг данных из всех источников в единую БД.
Для целей хранения, обработки и анализа данных используют реляционные базы данных. Наиболее известные - это проекты с открытым исходным кодом (PostgreSQL, MySQL, ClickHouse, Vertica и SQLite), а также коробочные решения, такие как Oracle, Microsoft SQL Server.
Шаг 0. Выбор сервера
Нет, это не опечатка)) Выбрав подходящую базу данных для аналитики, необходимо сделать шаг назад и понять, на каком сервере ее разворачивать.
Есть два варианта:
- Физический сервер компании. В данном случае управление архитектурой аналитического проекта также ляжет на плечи компании, но и контроль данных остается на стороне компании;
- Облачная платформа, например, Yandex Cloud. Облачные платформы на сегодняшний день прочно зарекомендовали себя как безопасное, доступное и стабильное решение, которое потребует меньшего ресурса компании.
Шаг 2. Коннектор данных
Коннектор данных - это инструмент для стриминга данных из рекламных кабинетов и из системы аналитики в единую БД.
Итак, у нас есть развернутое облачное хранилище или сервер, и на нем установлена база данных. Наступает момент наполнения базы данных.
У нас есть несколько вариантов наполнения БД:
- API
Мы можем самостоятельно писать запросы на выгрузку данных из рекламных кабинетов и систем аналитики в базу данных с помощью API. Однако это достаточно ресурсозатратный процесс, т.к. требует получения доступов (токенов), написания скрипта и его дебага.
- Коннекторы данных
Есть готовые решения, которые за символическую плату предоставляют инструмент, который в несколько кликов поможет настроить потоки данных практически из любого источника в практически любой приемник.
Мы обычно используем в своей работе собственный коннектор данных DataGo! Pipelines*.
*DataGo! Pipelines - Импортирует данные о рекламных расходах из Яндекс.Директ, ВКонтакте, myTarget, “сырые” данные по событиям AppsFlyer и из др.систем. Объединив данные сайта, мобильного приложения и рекламных кабинетов, маркетолог получает достоверную оценку рекламных усилий.
Шаг 3. Диспетчер тегов
Запуск рекламных кампаний в online неразрывно связан с установкой рекламных пикселей на сайте рекламодателя. Данные пиксели позволяют отслеживать статистику на сайте и передавать эти данные на сторону рекламной площадки, где они будут отображаться в личном кабинете.
Когда речь идет о запуске медийной рекламы, то обычно на сайт устанавливается пиксель трекера (например, Adriver или Weborama).
Данные пиксели размещаются напрямую в код сайта с помощью front-разработчиков, но когда речь идет о большом количестве рекламных кампаний и пикселей, то необходимо воспользоваться диспетчером тегов, который позволяет в едином интерфейсе без привлечения ресурса front-разработки устанавливать множество рекламных пикселей.
На данный момент в России доступен Google Tag Manager. Но все же риск его отключения есть и на замену большинство компаний рассматривают Matomo Tag Manager, который доступен как в коробочной версии так и в on-premise формате.
Шаг 4. Инструмент для оркестрации данных
Работа с большим количеством данных неизбежно приводит к появлению множества скриптов, которые при этом надо запускать по расписанию - регулярно получать данные из источников, находить в них ошибки, обрабатывать их и придавать им бизнес-смысл - готовить для визуализации, строить прогнозы, высчитывать метрики и так далее.
Для поддержания порядка и своевременного запуска фрагментов кода необходимо использовать инструменты для оркестрации данных(например, Apache Airflow). Это open-source решение, своеобразный стандарт в индустрии работы с данными.
Что это значит?
Это значит, что ваши специалисты по анализу данных уже умеют с ним работать, или смогут научиться довольно быстро. Airflow имеет огромный набор встроенных инструментов и провайдеров, которые позволяют манипулировать с различными источниками данных: S3, ClickHouse, BigQuery, Google Docs, FTP. Он также позволяет создавать собственные операторы и комфортно подключать различные инструменты, например dbt. Airflow необходимо устанавливать на виртуальную машину, а ВМ можно купить в Yandex Cloud.
Шаг 5. Dbt
Dbt - это инструмент для разработки и тестирования моделей данных. Он позволяет создавать модели (таблицы и представления), материализовывать их в базе данных без сложного синтаксиса, обновлять модели в правильном порядке, использовать для них встроенные тесты или писать свои, документировать модели, их источники и дашборды, отслеживать взаимосвязь между моделями, работать с sql как с кодом и многое другое.
Это также open-source инструмент, хотя у него есть и облачная версия dbt Cloud. Работа с dbt значительно облегчает работу с базами данных для дата-инженеров и аналитиков, снижает время на разработку за счет переиспользования кода и время на поддержку благодаря контролю версий. dbt нужен всем, кто ловил себя на мысли, что не понимает, откуда в базе данных эта таблица, насколько качественные в ней данные и можно ли ей доверять.
Шаг 6. Git
Git - система контроля версий, без которой нельзя представить современную разработку. Она необходима для того, чтобы поддерживать в актуальном состоянии код: трансформации в Airflow, модели dbt или что угодно ещё - там, где есть код, нужен контроль версий.
Каждый специалист по работе с данными в компании должен понимать, кто и в какое время вносил изменения в код - это значительно снижает время на поддержку, ускоряет разработку и предохраняет от критических ошибок.
Шаг 7. BI система
Любую аналитику необходимо донести до конечных заказчиков в понятном виде. Для этого необходимо визуализировать полученные результаты. В этом нам помогают BI системы.
У BI систем широкий круг возможностей, но в аналитике мы используем их в первую очередь для построения отчетности (дашбордов).
Есть около десятка самых популярных систем. Выбор системы зависит от многих факторов:
- доступность оплаты из РФ;
- коробочный вариант или on-premise;
- удобство использования;
- интеграция с текущим стеком технологий.
Стоит также обращать внимание на возможность масштабируемости конечных дашбордов.
Когда речь идет про post-view аналитику мы имеем дело с очень большим объемом данных. Каждый новый флайт в идеале выделять в отдельный дашборд, чтобы мощностей BI системы хватило на обработку миллионов строк данных.
При условии, что медийная реклама запускается достаточно часто, аналитикам будет намного быстрее делать отчеты в таких BI, в которых можно скопировать шаблон дашборда и переподключить источники. Из коробочных это Power BI, из облачных - Superset и Metabase.
Делали сравнение облачных BI-систем, можно посмотреть тут: https://docs.google.com/spreadsheets/d/1XZzBqZmqfnFsHun1IKElGZGbrb8VjbVBR9iMsxt7XiE/edit#gid=0
Шаг 8. “Холодное” хранилище
Итак, все необходимые данные собраны в базе данных, обработаны, проанализированы и визуализированы. Можно подумать, что на этом можно остановиться.
Но необходимо задуматься об оптимизации бюджета на хранение данных.
Дело в том, что данные, которые хранятся непосредственно в БД могут занимать “полезное пространство” и увеличивать стоимость вашей базы. Чтобы оптимизировать расходы на хранение, рекомендуется исторические данные, которые не используются активно в аналитике, но требуют хранения, переносить в “холодное” хранилище.
“Холодное” хранилище - это разновидность объектного хранилища, которая отличается низкой стоимостью хранения данных, но при этом более высокой, по сравнению с “горячим”, стоимостью запросов из него или более низкой скоростью выборки данных. Найти “холодное” объектное хранилище можно например в Google Cloud Storage или Yandex Object Storage.
Итоговая схема
Визуально схема сбора, обработки, анализа и визуализации данных выглядит вот так:
Сбор, обработка и хранение данных - это сложный и длительный процесс, требующий не только выделенного бюджета, но и специалистов с релевантным опытом работы, разбирающихся в технологических тонкостях с учетом изменений рынка, времени на реализацию и готовность столкнуться с подводными камнями.
